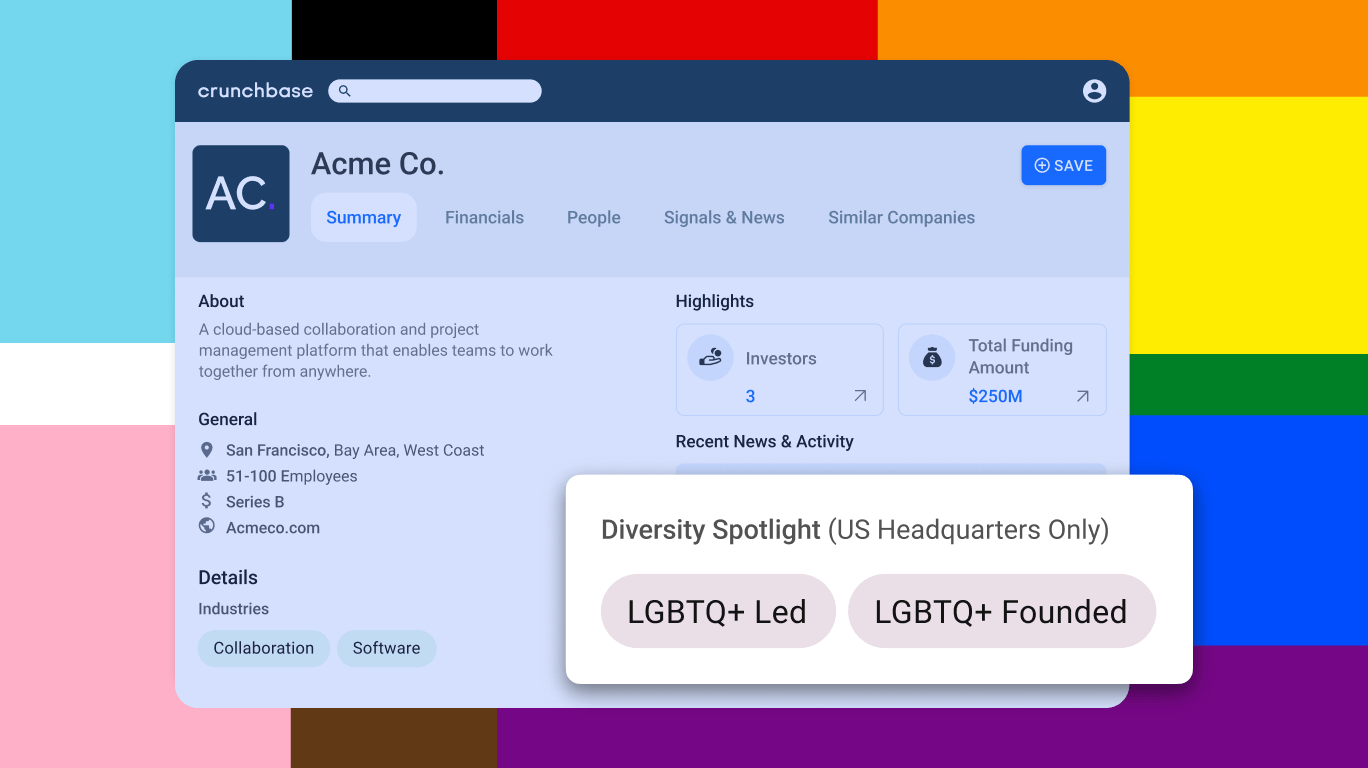
News About Crunchbase 4 min read Fostering Inclusivity: New Crunchbase LGBTQ+ Diversity Spotlight Tags Crunchbase's new “LGBTQ+ led” and “LGBTQ+ founded” tags will help close the funding gap and raise visibility for LGBTQ+ entrepreneurs. Diane Kerolus, Group Product Manager at Crunchbase
Sales 7 min read AI in Sales: What to Know in 2024 AI in sales is the use of artificial intelligence to simplify, optimize and improve sales processes. Learn how sales automation can drive revenue growth. Rebecca Strehlow, Copywriter at Crunchbase
Entrepreneurs 9 min read 27 Best AI Tools to Use in 2024 Learn about the best AI tools today. Explore how AI software can accelerate your workflow and generate revenue for your business. Rebecca Strehlow, Copywriter at Crunchbase
Investors 6 min read The Risks and Rewards of ChatGPT Becoming a VC Tool Generative AI is already part of the investment industry, and it's not going anywhere. We must consider the risks of ChatGPT moving forward. Mikhail Taver, Founder and Managing Partner of Taver Capital